Puppeteer 是什么以及如何在网络抓取中使用它 | 2024 完整指南

Emma Foster
Machine Learning Engineer

网页抓取已经成为任何处理网页数据提取的人都必须掌握的一项重要技能。无论你是开发者、数据科学家还是希望从网站收集信息的爱好者,Puppeteer都是你可以使用的最强大工具之一。本完整指南将深入探讨什么是Puppeteer以及如何有效地在网页抓取中使用它。
Puppeteer简介
Puppeteer是一个Node库,它通过DevTools协议提供了一个高级API来控制Chrome或Chromium。它由Google Chrome团队维护,提供了开发者执行各种浏览器任务的能力,如生成截图、抓取网站,最重要的是网页抓取。由于其无头浏览功能(即可以在没有图形用户界面的情况下运行),Puppeteer非常受欢迎,非常适合自动化任务。
是否在为反复失败的验证码而苦恼?通过CapSolver AI驱动的自动网页解锁技术,发现无缝的自动验证码解决方案!
领取您的优惠码以获得顶级验证码解决方案;CapSolver: WEBS。兑换后,每次充值将额外获得5%的奖励,无限次。

为什么使用Puppeteer进行网页抓取?
虽然Axios和Cheerio是JavaScript网页抓取的不错选择,但它们有一些限制:处理动态内容和绕过反抓取机制。
作为一个无头浏览器,Puppeteer在抓取动态内容方面表现出色。它可以完全加载目标页面,执行JavaScript,甚至可以触发XHR请求以检索额外的数据。这是静态抓取器无法实现的,尤其是在单页应用程序(SPA)中,初始HTML缺乏重要数据。
Puppeteer还能做什么?它可以渲染图像、捕获截图,并具有解决各种验证码的扩展,如reCAPTCHA、captcha、captcha。例如,你可以编写脚本在页面上导航,在特定时间间隔内截取截图,并分析这些图像以获得竞争性见解。可能性几乎是无限的!
Puppeteer的简单使用
我们之前使用Selenium和Python完成了ScrapingClub的第一部分。现在,让我们使用Puppeteer完成第二部分。
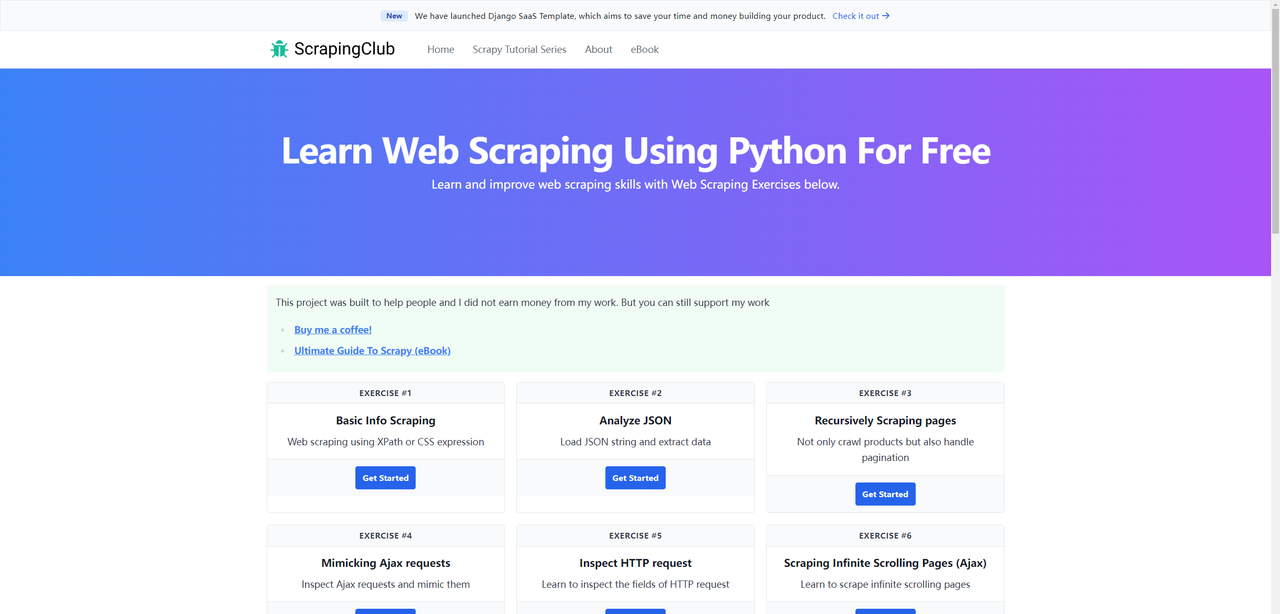
在开始之前,请确保你在本地机器上安装了Puppeteer。如果没有,你可以使用以下命令安装:
bash
npm i puppeteer # 安装时下载兼容的Chrome。
npm i puppeteer-core # 或者,作为库安装,不下载Chrome。访问网页
javascript
const puppeteer = require('puppeteer');
(async function() {
const browser = await puppeteer.launch({headless: false});
const page = await browser.newPage();
await page.goto('https://scrapingclub.com/exercise/detail_json/');
// 暂停5秒
await new Promise(r => setTimeout(r, 5000));
await browser.close();
})();puppeteer.launch方法用于启动一个新的Puppeteer实例,可以接受一个包含多个选项的配置对象。最常见的是headless选项,它指定是否以无头模式运行浏览器。如果不指定此参数,默认值为true。其他常见的配置选项如下:
| 参数 | 类型 | 默认值 | 描述 | 示例 |
|---|---|---|---|---|
args |
string[] |
启动浏览器时传递的命令行参数数组 | args: ['--no-sandbox', '--disable-setuid-sandbox'] |
|
debuggingPort |
number |
指定调试端口号 | debuggingPort: 8888 |
|
defaultViewport |
dict |
{width: 800, height: 600} |
设置默认视口大小 | defaultViewport: {width: 1920, height: 1080} |
devtools |
boolean |
false |
是否自动打开开发者工具 | devtools: true |
executablePath |
string |
指定浏览器可执行文件的路径 | executablePath: '/path/to/chrome' |
|
headless |
boolean 或 'shell' |
true |
是否以无头模式运行浏览器 | headless: false |
userDataDir |
string |
指定用户数据目录的路径 | userDataDir: '/path/to/user/data' |
|
timeout |
number |
30000 |
等待浏览器启动的超时时间(毫秒) | timeout: 60000 |
ignoreHTTPSErrors |
boolean |
false |
是否忽略HTTPS错误 | ignoreHTTPSErrors: true |
设置窗口大小
为了获得最佳浏览体验,我们需要调整两个参数:视口大小和浏览器窗口大小。代码如下:
javascript
const puppeteer = require('puppeteer');
(async function() {
const browser = await puppeteer.launch({
headless: false,
args: ['--window-size=1920,1080']
});
const page = await browser.newPage();
await page.setViewport({width: 1920, height: 1080});
await page.goto('https://scrapingclub.com/exercise/detail_json/');
// 暂停5秒
await new Promise(r => setTimeout(r, 5000));
await browser.close();
})();提取数据
在Puppeteer中,有多种方法可以提取数据。
-
使用
evaluate方法evaluate方法在浏览器上下文中执行JavaScript代码以提取所需数据。javascriptconst puppeteer = require('puppeteer'); (async function () { const browser = await puppeteer.launch({ headless: false, args: ['--window-size=1920,1080'] }); const page = await browser.newPage(); await page.setViewport({width: 1920, height: 1080}); await page.goto('https://scrapingclub.com/exercise/detail_json/'); const data = await page.evaluate(() => { const image = document.querySelector('.card-img-top').src; const title = document.querySelector('.card-title').innerText; const price = document.querySelector('.card-price').innerText; const description = document.querySelector('.card-description').innerText; return {image, title, price, description}; }); console.log('产品名称:', data.title); console.log('产品价格:', data.price); console.log('产品图片:', data.image); console.log('产品描述:', data.description); // 暂停5秒 await new Promise(r => setTimeout(r, 5000)); await browser.close(); })(); -
使用
$eval方法$eval方法选择单个元素并提取其内容。javascriptconst puppeteer = require('puppeteer'); (async function () { const browser = await puppeteer.launch({ headless: false, args: ['--window-size=1920,1080'] }); const page = await browser.newPage(); await page.setViewport({width: 1920, height: 1080}); await page.goto('https://scrapingclub.com/exercise/detail_json/'); const title = await page.$eval('.card-title', el => el.innerText); const price = await page.$eval('.card-price', el => el.innerText); const image = await page.$eval('.card-img-top', el => el.src); const description = await page.$eval('.card-description', el => el.innerText); console.log('产品名称:', title); console.log('产品价格:', price); console.log('产品图片:', image); console.log('产品描述:', description); // 暂停5秒 await new Promise(r => setTimeout(r, 5000)); await browser.close(); })(); -
使用
$$eval方法$$eval方法一次选择多个元素并提取其内容。javascriptconst puppeteer = require('puppeteer'); (async function () { const browser = await puppeteer.launch({ headless: false, args: ['--window-size=1920,1080'] }); const page = await browser.newPage(); await page.setViewport({width: 1920, height: 1080}); await page.goto('https://scrapingclub.com/exercise/detail_json/'); const data = await page.$$eval('.my-8.w-full.rounded.border > *', elements => { const image = elements[0].querySelector('img').src; const title = elements[1].querySelector('.card-title').innerText; const price = elements[1].querySelector('.card-price').innerText; const description = elements[1].querySelector('.card-description').innerText; return {image, title, price, description}; }); console.log('产品名称:', data.title); console.log('产品价格:', data.price); console.log('产品图片:', data.image); console.log('产品描述:', data.description); // 暂停5秒 await new Promise(r => setTimeout(r, 5000)); await browser.close(); })(); -
使用
page.$和evaluate方法page.$方法选择元素,evaluate方法在浏览器上下文中执行JavaScript代码以提取数据。javascriptconst puppeteer = require('puppeteer'); (async function () { const browser = await puppeteer.launch({ headless: false, args: ['--window-size=1920,1080'] }); const page = await browser.newPage(); await page.setViewport({width: 1920, height: 1080}); await page.goto('https://scrapingclub.com/exercise/detail_json/'); const imageElement = await page.$('.card-img-top'); const titleElement = await page.$('.card-title'); const priceElement = await page.$('.card-price'); const descriptionElement = await page.$('.card-description'); const image = await page.evaluate(el => el.src, imageElement); const title = await page.evaluate(el => el.innerText, titleElement); const price = await page.evaluate(el => el.innerText, priceElement); const description = await page.evaluate(el => el.innerText, descriptionElement); console.log('产品名称:', title); console.log('产品价格:', price); console.log('产品图片:', image); console.log('产品描述:', description); // 暂停5秒 await new Promise(r => setTimeout(r, 5000)); await browser.close(); })();
绕过反抓取保护
完成ScrapingClub的练习相对简单。然而,在实际的数据抓取场景中,获取数据并不总是那么容易。一些网站采用反抓取技术,可能会检测到你的脚本为机器人并将其封锁。最常见的情况是遇到验证码挑战,如captcha、captcha、recaptcha、captcha和captcha。
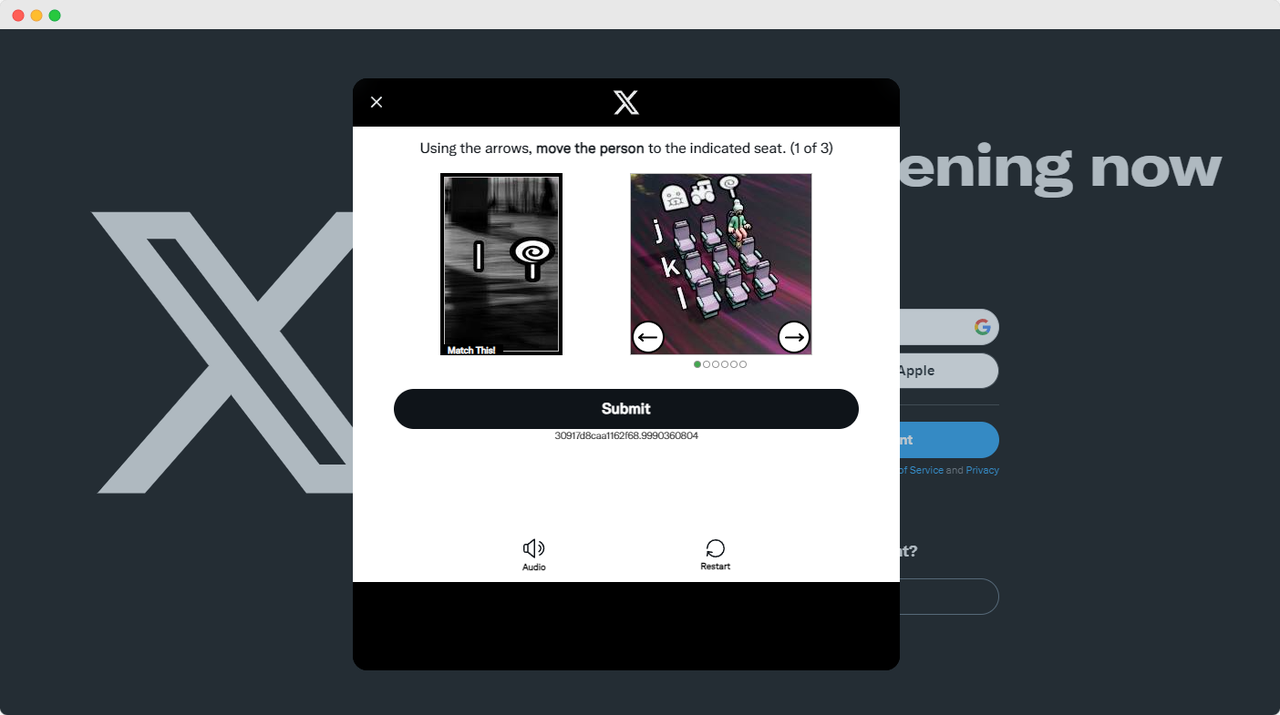
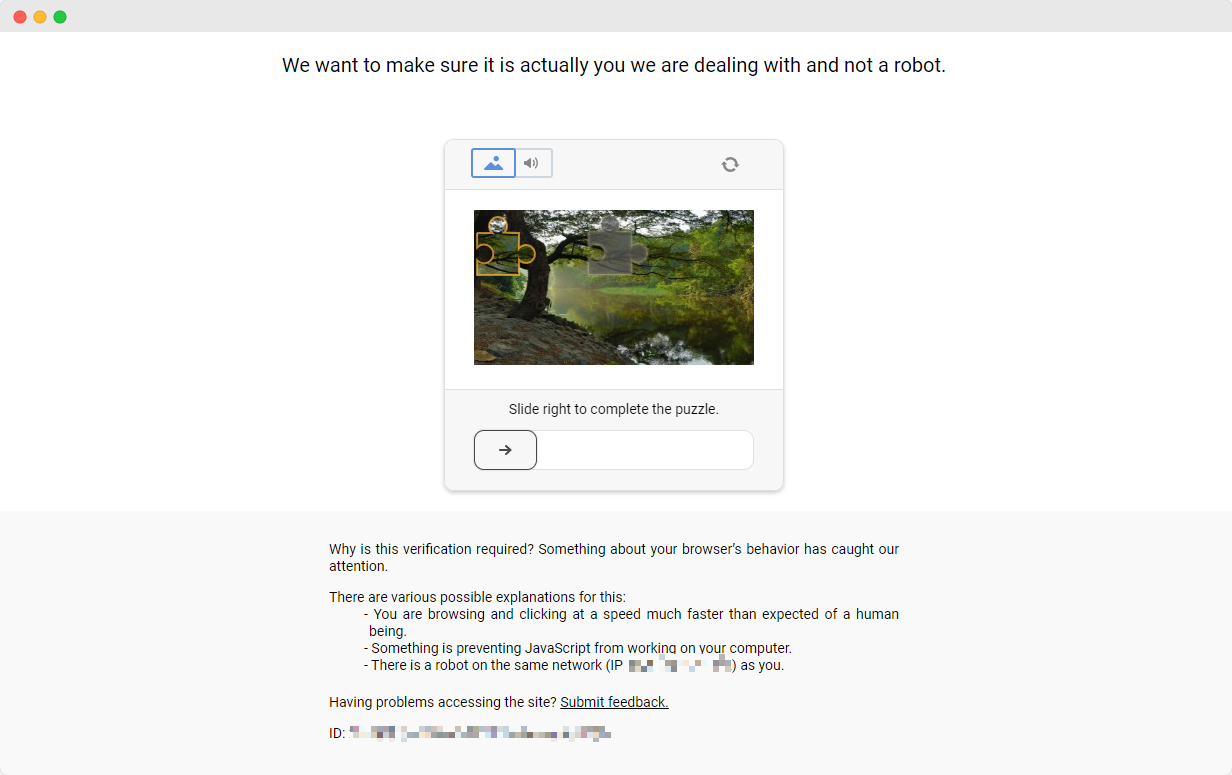
要解决这些验证码挑战,需要在机器学习、逆向工程和浏览器指纹对抗措施方面有丰富的经验,这可能需要大量时间。
幸运的是,你不再需要自己处理所有这些工作了。CapSolver提供了一个全面的解决方案,帮助你轻松解决所有挑战。CapSolver提供了一个浏览器扩展,允许你在使用Puppeteer进行数据抓取时自动解决验证码挑战。此外,它还提供了一个API方法来解决验证码并获取令牌。所有这些都可以在几秒钟内完成。查看这个文档以了解如何解决你遇到的各种验证码问题!
结论
网页抓取对于任何从事网页数据提取的人来说都是一项无价的技能,而Puppeteer作为一个具有高级API和强大功能的工具,是实现这一目标的最佳选择之一。其处理动态内容和绕过反抓取机制的能力使其在众多抓取工具中脱颖而出。
在本指南中,我们探讨了什么是Puppeteer,它在网页抓取中的优势,以及如何设置和有效使用它。我们通过示例演示了如何访问网页、设置视口大小以及使用各种方法提取数据。此外,我们讨论了反抓取技术带来的挑战以及CapSolver如何提供强大的解决方案来应对验证码挑战。


